Fudge Sunday - Cloud in Public: Engineering SLO
by Jay CuthrellShare and discuss on LinkedIn or HN
 This week we continue to take a look at public things for a public cloud.
This week we continue to take a look at public things for a public cloud.
☁️✅⚠️🛑
This issue is part 2 of a 5 part series
- Fudge Sunday - Cloud in Public: Status Dashboards
- Fudge Sunday - Cloud in Public: Engineering SLO
- Fudge Sunday - Cloud in Public: DevCommsOps
- Fudge Sunday - Cloud in Public: Mean Time To RCA
- Fudge Sunday - Cloud in Public: Impact Mapping
Definitions matter. Definitions will be pretty thick for this issue to focus on SLO, but we’ll make a quick stop to understand the SLI and the SLA as well.
In our first issue for the Cloud in Public series, we described cloud-related terminology such as status dashboards; it’s worth explaining the situations where ✅Green, ⚠️Yellow, or 🛑Red indicators might appear. ✅Green would represent a service being up or “OK” and ⚠️Yellow would mean the service degraded, whereas 🛑Red is when a service is down.
Now, let’s spend time thinking about indicators, the objectives that rely upon these indicators, and the agreements that capture the objectives.
SLI is an acronym for Service Level Indicator representing a quantitative measurement to say how ✅Up, ⚠️Degraded, or 🛑Down a service might be. Definitions must be precise for ✅Up, ⚠️Degraded, and 🛑Down. So, the SLI should represent an accurate measurement of a service attribute.
SLO is an acronym for Service Level Objective. Ideally, a service provider publishes the SLO as clearly and easily understood conditions in a written agreement. Engineering SLO is when a team of engineers can provide commensurate value that balances innovation delivery time and availability.
For example, the service provider may decide that a service should be available (✅Up/Green) 99.5% of the time in a month, which provides 0.5% of the month to perform maintenance which causes the service to perform (⚠️Degraded/Yellow) or other upgrade activities that would make the service unavailable (🛑Down/Red). Therefore, Engineering SLO is about balancing the need for rolling out new service features and the consistent availability of the service itself.
SLA is an acronym for Service Level Agreement which puts the SLO and SLI into a summary format that is written and often tied to a contractual or financial arrangement between the service provider and the end-user. In more blunt terms, the SLA constitutes the ability to charge for a service and present a bill to the end-user as a downstream customer of the service that has received value.
Error Budgets, Uptime, and SLO
At this point, we have wordy definitions of SLI, SLO, and SLA. So, let’s walk through some history of the terms so far. We’ll also introduce a few more neologisms along the way.
Back in the late 1980s, data center uptime and Internet access were becoming more commercially visible. Uptime Institute was founded during this time and became associated with the desirable traits of availability relating to various facilities-based service providers that underpinned a growing Internet and World Wide Web.
If you’ve ever heard the phrase “99% uptime,” then you know there is a remaining 1% that is not uptime. Saying the words “not uptime” is cumbersome, so the engineering term Error Budget is also used today in certain circles to convey the remaining 1% of the time that is not uptime.
Up to now, the S in our definition list has stood for service. Now, let’s assume services originate from a place (like a website) that we call a site.
At this point, you might be wondering where Site Reliability Engineering originated. Site Reliability Engineering is a neologism created by someone, but it might not be on NPR’s A Way With Words just yet. We’ll get to that next.
With technology cultural movements such as DevOps, there have been disciplines formed within organizations such as Google. Historically, Ben Treynor Sloss joined Google in 2003 and has shared some of the Site Reliability Engineering (SRE) stories during his career.
Of note, in 2007, the Amazon S3 Service Level Agreement was first published. Of particular note, Service Credits represent a failure to reach the SLO. Service Credits mean that end-users would get a 10% to 25% credit if Amazon S3 could not reach specific Monthly Uptime Percentages (99.9-99% and below 99%, respectively).
In 2014, blog posts from SRE teams at Google introduced wider audiences to terminology such as Error Budgets. So, at this point, if you want to spend an hour on the story of SRE – enjoy this “Keys to SRE” from Ben Treynor Sloss. (also available on YouTube)
A few years later, in 2018, Google published more content on these topics. For the first time, we could get definitions from a Site Reliability Engineer who lives and breathes SLIs, SLOs, and SLAs to keep their sites more reliable.
By 2019, Amazon S3 Service Level Agreement had been updated several times.
- October 1, 2007
- June 1, 2013
- April 4, 2018
- December 31, 2018
- March 20, 2019
- May 1, 2019
- July 31, 2019
Generally, each updated expansion tier, functionality, availability, and reliability associated with S3 have resulted in service credits calculations updates.
Besides AWS, there are vibrant discussions around SLO today from the uptime-oriented community of thinkers and doers. For example, Charity Majors (aka @mipsytipsy) is the CTO and co-founder of Honeycomb.io and makes a case for SLO being an API for engineering teams.
Selected Twitter references
Finding online references to SRE, SLI, SLO, SLO, Error Budget, and other related terms like observability using a popular search engine may result in marketing SEO results. However, an exciting alternative is to search Twitter for conference imagery of presentations.
Below are selected Twitter references in chronological order from:

Finally the most concise and clear explanation of the difference between SLI, SLO and SLA ever.
“SLIs drive SLOs which inform SLAs.”
https://t.co/tNE5zXKQMD https://t.co/lVELDj2sEm

This is the clearest SLI/SLO/SLA explanation I’ve seen so far. From @elisabPDX and @mflaming at SRECon Americas. I’m using this formulation to describe it from now on. https://t.co/VzVKwqmQgy

Once you have an SLO that’s really not an SLO since the users have come to expect better, then you’re unable to take any risks. Systems that are *too* reliable can become problematic too. #VelocityConf https://t.co/KsZ8CQxkJk

SLO / SLI / SLA crisp definitions with @ahidalgosre from @squarespace #systemsatscale @at_scale_events https://t.co/ILTF7pLwtH
@JayCuthrell @rakyll @whereistanya @copyconstruct @lizthegrey @mipsytipsy Oh so that’s literally just a tweet of me taking a photo of @ahidalgosre at DevOps Days. If you want to see things I’m doing with SLOs atm check out my TLs talk at SLOConf https://t.co/myjpcOxGcl
 SLOconf: SLOs at Facebook - by Posten A
SLOconf: SLOs at Facebook - by Posten A
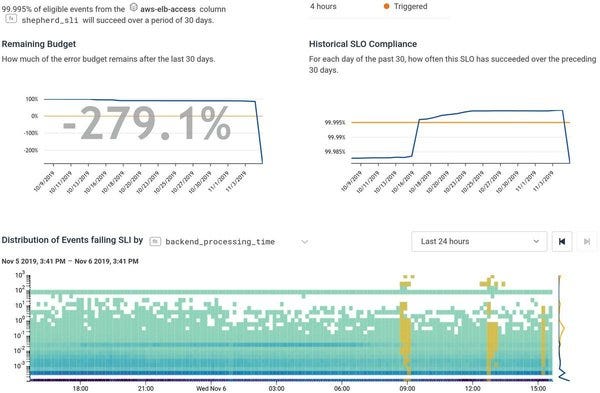
@QuinnyPig This is the impact on our SLO (it’s _bad_): https://t.co/d3AXBVGyH3
Updated definition:
📉 Monitoring is for running and understanding other people’s code (aka “your infrastructure”)
📈 Observability is for running and understanding *your* code – the code you write, change and ship every day; the code that solves your core business problems. https://t.co/P4xIp2xs9K
Disclosure
I am linking to my disclosure.
Topics:
✍️ 🤓 Edit on Github 🐙 ✍️
Share and discuss on LinkedIn or HN
-
Get Fudge Sunday each week